Как правильно настроить файл robots.txt?

Файл robots.txt управляет индексацией сайта. В нем содержатся команды, которые разрешают или запрещают поисковым системам добавлять в свою базу определенные страницы или разделы на сайте. Например, на Вашем сайте имеется раздел с конфиденциальной информацией или служебные страницы. Вы не хотите, чтобы они находились в индексе поисковых систем, и настраиваете запрет на их индексацию в файле robots.txt.
В данной статье мы рассмотрим, как настроить robots.txt и проверить правильность указанных в нем команд. Как закрыть от индексации сайт целиком или отдельные страницы или разделы.
Чтобы поисковые системы нашли файл, он должен располагаться в корневой папке сайта и быть доступным по адресу ваш_сайт.ru/robots.txt. Если файла на сайте нет, поисковые системы будут считать, что можно индексировать все документы на сайте. Это может привести к серьезным проблемам, в частности, попаданию в базы страниц-дублей, документов с конфиденциальной информацией.
Структура файла robots.txt
В файле robots.txt для каждой поисковой системы можно прописать свои команды. Например, на скриншоте ниже Вы можете увидеть команды для робота Яндекса, Google и для всех остальных поисковых систем:
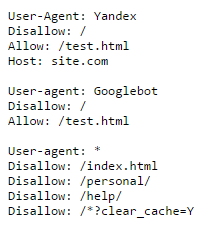
Каждая команда начинается с новой строки. Между блоками команд для разных поисковых систем оставляют пустую строку.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
| Disallow: | Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи). |
| Allow: | Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow. |
| Host: | Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом. |
| Sitemap: | В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте. |
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: * Disallow: / |
Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: * Disallow: / Allow: /test.html |
Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
- Звездочка * заменяет собой любую последовательность символов.
- По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
| Команда | Что обозначает |
| Disallow: /basket/ | Запрещает индексацию всех документов в разделе /basket/, например: site.com/basket/ site.com/basket/2/ site.com/basket/3/ site.com/basket/4/ |
| Disallow: /basket/$ | Запрещает индексацию только документа: site.com/basket/ Документы: site.com/basket/2/ site.com/basket/3/ site.com/basket/4/ остаются открытыми для индексации. |
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Как проверить файл robots.txt?
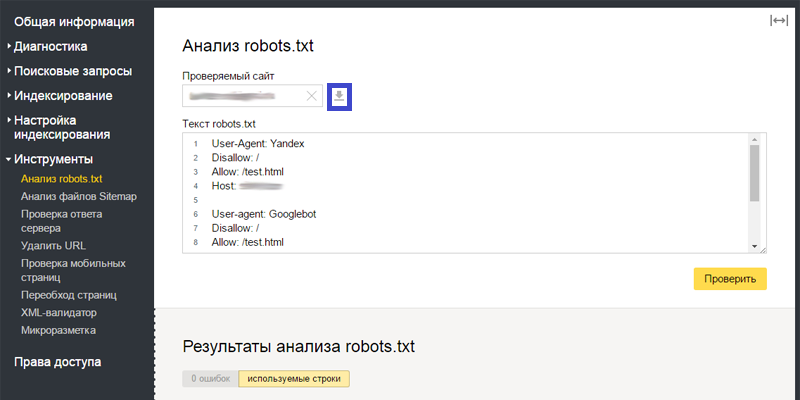
После добавления файла robots.txt на сайт Вы можете проверить корректность его настройки. Для этого поисковые системы предлагают специальные инструменты. В статье рассмотрим инструмент от Яндекса, который позволяет проверить правильность настройки robots.txt. Он доступен в сервисе Яндекс.Вебмастер во вкладке «Инструменты» – «Анализ robots.txt».
В верхней части страницы Вы можете увидеть проверяемый сайт (на скриншоте затерт), содержание файла robots.txt, известное Яндексу. Обязательно проверьте, что содержание файла указано корректно. Если в Яндекс.Вебмастер выводятся старые команды, нажмите на кнопку «Загрузить» (серый значок справа от ссылки на проверяемый сайт, выделен на скриншоте рамкой):
В нижней части страницы добавьте в поле «Разрешены ли URL?» список страниц, по которым Вы хотите проверить, разрешена их индексация или нет. Нажмите кнопку «Проверить», и ниже выведутся результаты. Красный значок означает, что страница запрещена к индексации, зеленый – разрешена:
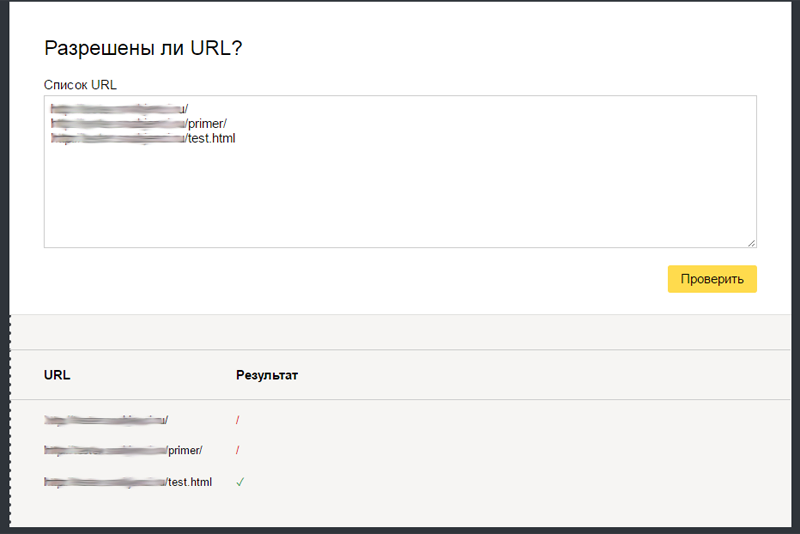
Аналогичные инструменты проверки файла имеются в Центре вебмастеров Google.
Время от времени в структуру сайта вносятся изменения. Поэтому необходимо периодически проверять, какие страницы и документы находятся в индексе поисковых систем. При появлении в индексе документов, которые не должны там быть, их индексацию необходимо закрыть в файле robots.txt.
Отправить комментарий

В рамках оптимизации текстов на сайте в контент вносятся изменения, необходимые для улучшения позиций в поисковых системах. Например, повышается ...

Выбор ключевых слов – один из важнейших этапов продвижения сайта. Все дальнейшие усилия не принесут эффекта, если Вы неправильно подберете ...